Measuring and Enhancing Trustworthiness of LLMs in RAG through Grounded Attributions and Learning to Refuse
- ICLR 2025 Oral
- 논문 원문
들어가며
RAG를 만드는 분들은 하나같이 LLM에 대한 걱정을 많이 할 것이다. 특히, 보안이 중요한 문서로 RAG 시스템을 구축할 때에는 오픈소스 모델을 사용할 수 밖에 없고, 만약 가용할 수 있는 GPU 자원이 제한되어 있다면 70B 정도의 중간 정도 크기의 모델도 활용하기 힘든 경우가 정말 부지기수이다.
문제는 7B, 13B같은 sLLM을 사용할 때에 발생하는데, LLM의 능력 때문에 RAG의 Retrieval 성능이 나쁘지 않아도 최종 답변이 안 좋아지는 경우가 있기 마련이다.
이러한 상황, 혹은 다른 분들의 상황을 볼 때면, 내가 할 수 있는 조언은 "좋은 LLM을 쓰세요."와 같은 뜬구름 잡는 것 같은 발언 밖에는 없었다.
이 논문에서는 이런 상황에 대처할 수 있는 하나의 방법을 알아본다.
더불어서, RAG의 성능을 높이는 데에 어쩌면 경시되었던 "LLM의 RAG 태스크에서의 성능"을 측정하고 향상시킬 수 있는 방법을 탐구할 것이다.
요약
- RAG 태스크에서 LLM이 가져야만 하는 중요한 능력은 무엇일까?
- 첫 째로, 모르는 것을 모른다고 말하는 능력이 있다. 주어진 문서에 적절한 정보가 주어져 있지 않다면, 본인이 알고 있던 부정확한 지식(parametric knowledge)보다는 모른다고 말하는 것이 훨씬 좋을 것이다.
- 둘 째로, 답변에 정확하게 답해야 할 것이다.
- 마지막으로, 어느 문서에서 답변을 가져왔는지 그 citation (출처)를 올바르고 정확하게 표시하는 능력이 필요하다.
- 이 논문에서는 Retrieval이 아닌 위에서 언급한, RAG 태스크에서의 LLM의 능력의 측정과 향상에 집중한다.
- 이를 위해 새로운 evaluation metric인 Trust Score를 제안하고, 이것을 향상시키기 위한 방법인 Trust Align을 제안한다.
RAG에서의 Hallucination 종류
RAG에서 hallucination을 줄이는 것은 정말 핵심 of 핵심이다.
그 종류를 논문에서는 다음과 같이 나눈다.
- 부정확한 답변
- 과도한 응답 - 모른다고 답했어야 하는 것을 안다고 답변을 한다.
- 잘못된 거절 - 안다고 답변해야 하는 것을 모른다고 답변을 거부한다.
- 과도한 citation - 쓸데 없는 citation을 생성한다.
- 부적절한 citation - 답변을 뒷받침하지 않는 citation을 생성한다.
Trust Score
기존 메트릭의 문제
기존 메트릭인 Response Truthfulness는 gold claim 중에서 얼마나 많은 claim이 생성된 답변이 포함되었는지, 그 Recall을 계산한다.
하지만, 이는 gold claim이 정작 retrieve된 문서 내에서는 없는 경우를 포함하지 못한다. LLM은 자신이 알고 있던 parametric knowledge를 바탕으로 답변을 하여, gold claim을 맞출 수도 있다는 것이다.
이상적인 LLM은 Document 내에 있는 정보만 맞출 수 있고, 그렇지 않은 정보에 기반한 답변은 하지 않아야 한다. 그래서, 기존 메트릭은 'gold claim이 문서 내에 없을 경우'에 만점을 절대 받을 수가 없다.
Trust Score는 이런 문제를 해결한다.
1. Grounded Refusals
요약하면, Unanswerable 및 Answerable 문제들에 대하여 각각의 F1 score를 계산한 후 두 F1 score를 평균한 값이다.
먼저
- Precision - 모델이 모른다고 답변했을 경우에, 실제로 답변이 불가능한 질문이었을 비율.
- Recall - 실제로 답변이 불가능한 질문 중, 모델이 모른다고 답변한 비율.
는 precision과 recall의 조화평균.
또한,를 다음과 같이 계산한다. - Precision - 모델이 답변을 이야기 한 경우에, 실제로 답변이 가능한 질문이었을 비율.
- Recall - 실제로 답변이 가능한 질문 중, 모델이 답변을 이야기한 비율.
는 precision과 recall의 조화평균.
와 의 평균이 최종 Grounded Refusals 메트릭의 값이 된다.
2. Answer Correctness
기존 메트릭과 달리, gold claim이면서 document 내에 존재하는 claim들만 gold claim으로서 설정한다.
Dataset-wide 스코어링은 다음과 같이 진행한다.
- Precision - LLM이 실제로 답변한 질문들의 정답 점수의 평균
- Recall - Answerable한 질문들의 LLM 정답 점수의 평균
- Precision과 recall의 조화평균
3. Grounded Citations
모델이 만든 citation의 정확도를 측정하는 것이 목적이다.
이 역시 citation에 대한 precision과 recall을 측정한 후, F1 score를 최종 값으로 사용한다.
- Precision - LLM이 생성한 citation들이 그것에 연관되어 있다고 표시된 statetment를 뒷받침 하고 있는가? (분모가 citation의 개수)
- Recall - 각 statement들의 citation이 해당 statement를 뒷받침 하고 있는가? (분모가 citation의 개수)
해당 메트릭은 LLM이 답변을 수행한 답변들에 대해서만 계산한다.
4. 최종 Trust Score
위 3가지 메트릭 (Grounded Refusals, Answer Correctness, Grounded Citations)의 평균이 최종 Trust Score가 된다.
Trust Align
이제 LLM이 RAG Task에 알맞게 훈련될 수 있도록, 이를 위한 데이터셋을 구축하고 DPO를 통하여 파인튜닝 하고자 한다. Trust Align은 이 DPO 훈련을 위한 데이터셋 생성 과정이다.
해당 데이터셋은 쿼리, retrieve 된 문서들, 그리고 모범 답변과 잘못된 답변의 pair로 구성된다.
만약 쿼리가 unanswerable인 경우, 모범 답변은 거절 문구고, 잘못된 답변은 거절하지 않는다.
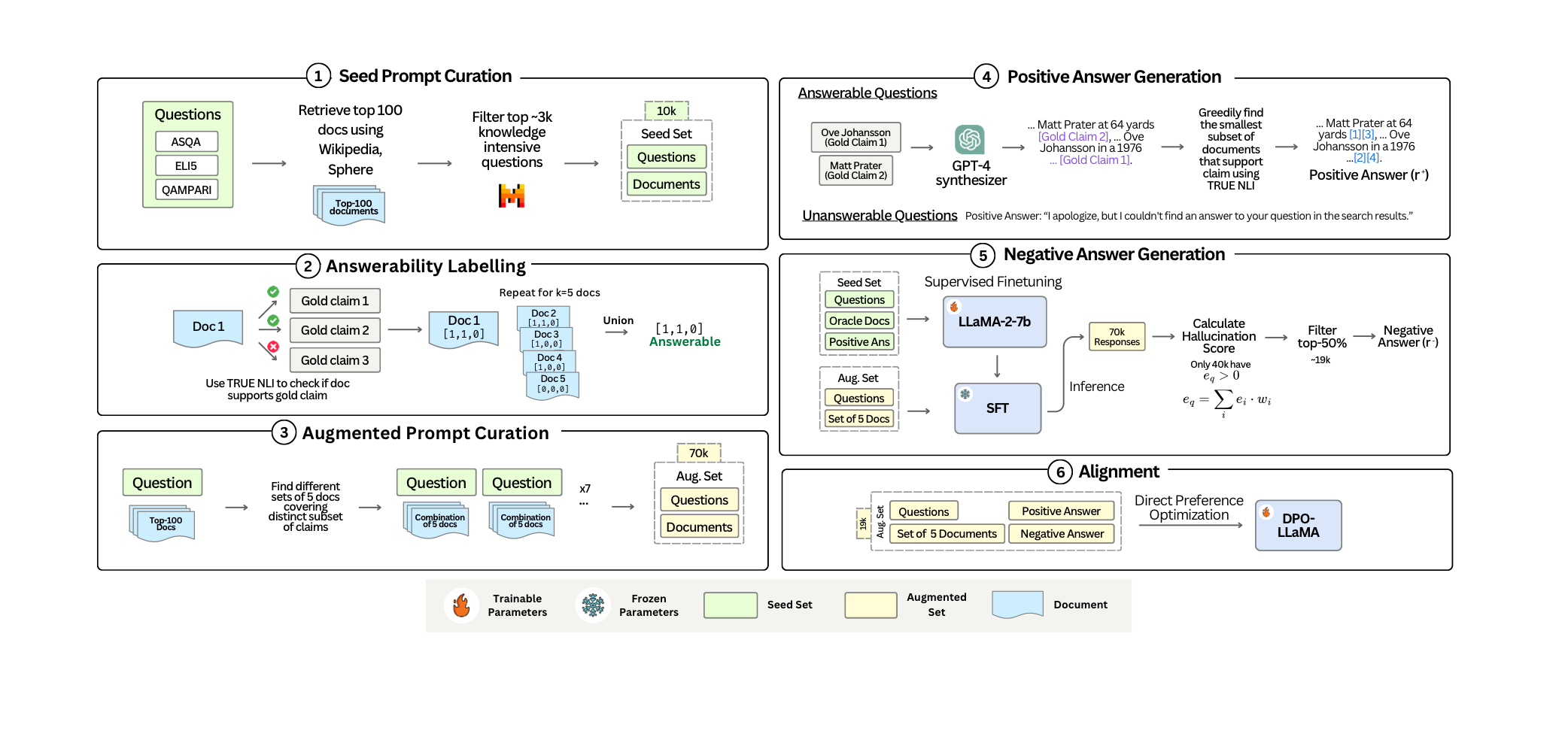
아래 과정을 통해서 데이터셋을 생성한다.
- 고품질이고 다양한 질문들을 얻는다.
- ASQA, QAMPARI, Eli5 데이터셋을 seed 데이터셋으로 사용했다.
- Mistral-8x7B를 통해 질문 난이도를 1~7단계로 구분하고, 4단계 이상의 어려운 질문만 사용했다.
- 각 질문들을 뒷받침하는 문서를 얻는다.
- 각 seed 질문들에 대한 문서들을 100개씩 retrieve한다. 만약 관련 문서가 단 하나도 없었다면 제거했다.
- 100개 중 가장 관련있는 5개를 골라서 oracle 문서들로 지정한다.
- 질문과 문서 pair를 여러 Hallucination 타입들을 커버할 수 있도록 조정한다.
- oracle 문서들과 100개의 문서들을 랜덤으로 섞어가며, 여러 종류의 q-d 페어를 만들었다.
- unanswerable을 만들 때에는 gold claim과 굉장히 유사하나, 쿼리와는 관련이 없는 문서들을 골라 넣어주었다.
- 모범 답변을 생성한다.
- Answerable 답변의 경우, GPT-4를 이용하여 모범 답변을 생성했다.
- 각 statement들에 대하여, NLI 모델을 사용해 가장 관련있는 문서들을 골라 citation으로 추가해 주었다.
- Unanswerable의 경우 거절 멘트를 넣어주었다.
- 여러 Hallucination 타입들을 담은 잘못된 답변을 생성한다.
- 고품질의 잘못된 답변 생성을 위해, llama-2-7b 모델을 SFT로 파인튜닝했다.
- 이 때, seed 데이터셋을 이용해 파인튜닝 했다.
- 이후, 모든 q-d 페어를 넣어 답변을 생성하고, 그 중 hallucination이 존재하는 답변들을 필터링 하였다.
- 결과적으로 70k개의 샘플들 중 좋은 잘못된 답변으로 판단이 된 19k개의 샘플에 대해 DPO를 수행하였다.
실험 결과
- 각 질문에 5개의 문서들을 넣어 주었다.
- Llama 시리즈, Qwen 시리즈, Phi3.5-mini의 오픈 소스 모델들을 실험에 사용했다.
- 훈련에 사용했던 ASQA, QAMPARI, Eli5 데이터셋의 테스트 셋을 평가에 사용했고, out-of-domain 실험을 위하여 ExpertQA도 사용했다.
- 기본적인 In-context Learning 뿐 아니라, 아래와 같은 방법들을 테스트했다.
- PostCite : LLM이 질문만 보고 답변을 만들고, 그 답변을 기반으로 가장 유사한 문서들을 retrieve한다 (Graph-Table-RAG 이용)
- PostAttr : PostCite와 비슷하지만, citation 생성을 위해 NLI 모델을 사용한다.
- Self-RAG : LLM이 직접 retrieval을 활용할 수 있도록 훈련되었다.
- FRONT : citation 생성을 위해 LLM을 파인튜닝 할 수 있는 프레임워크
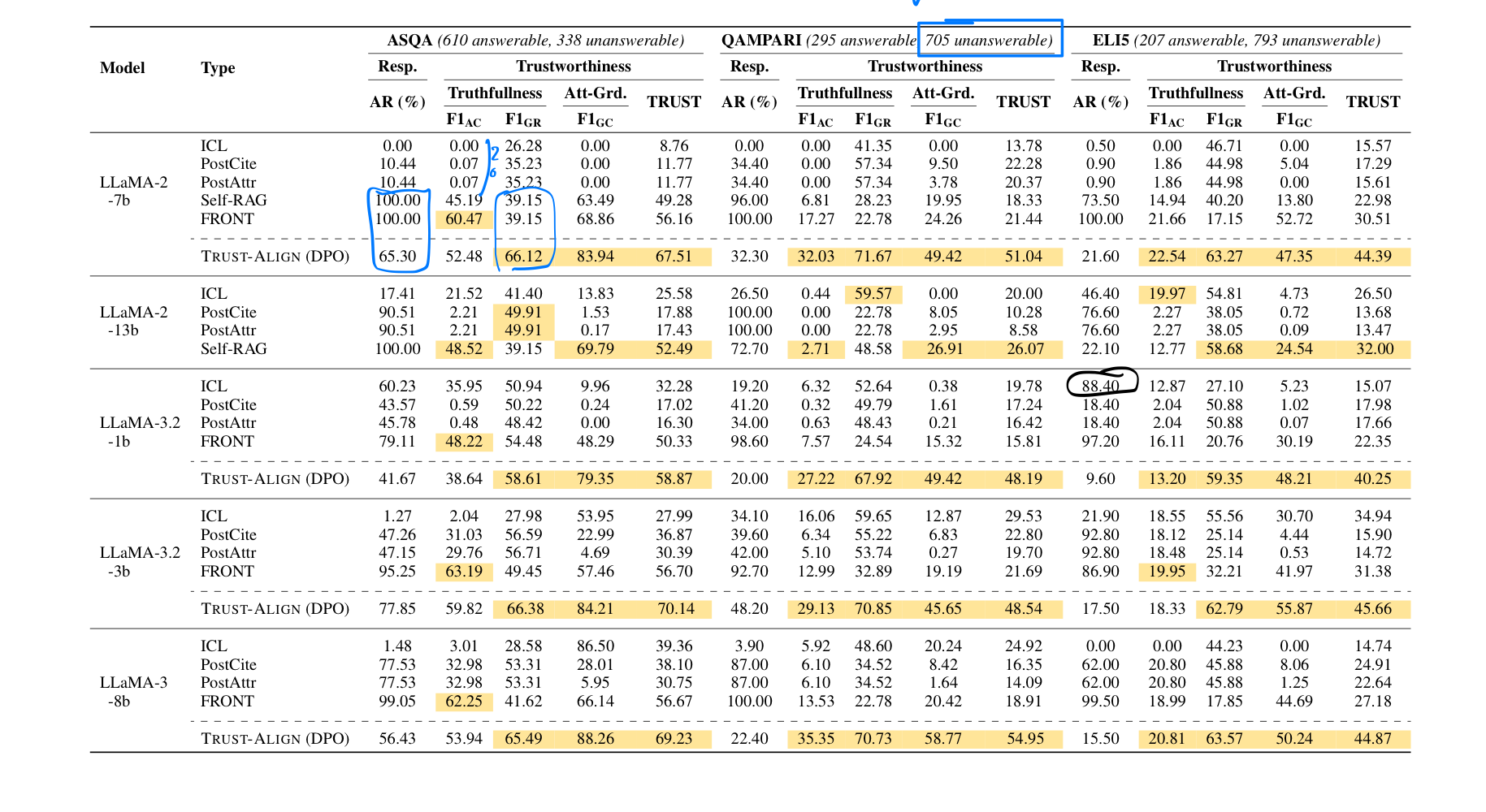
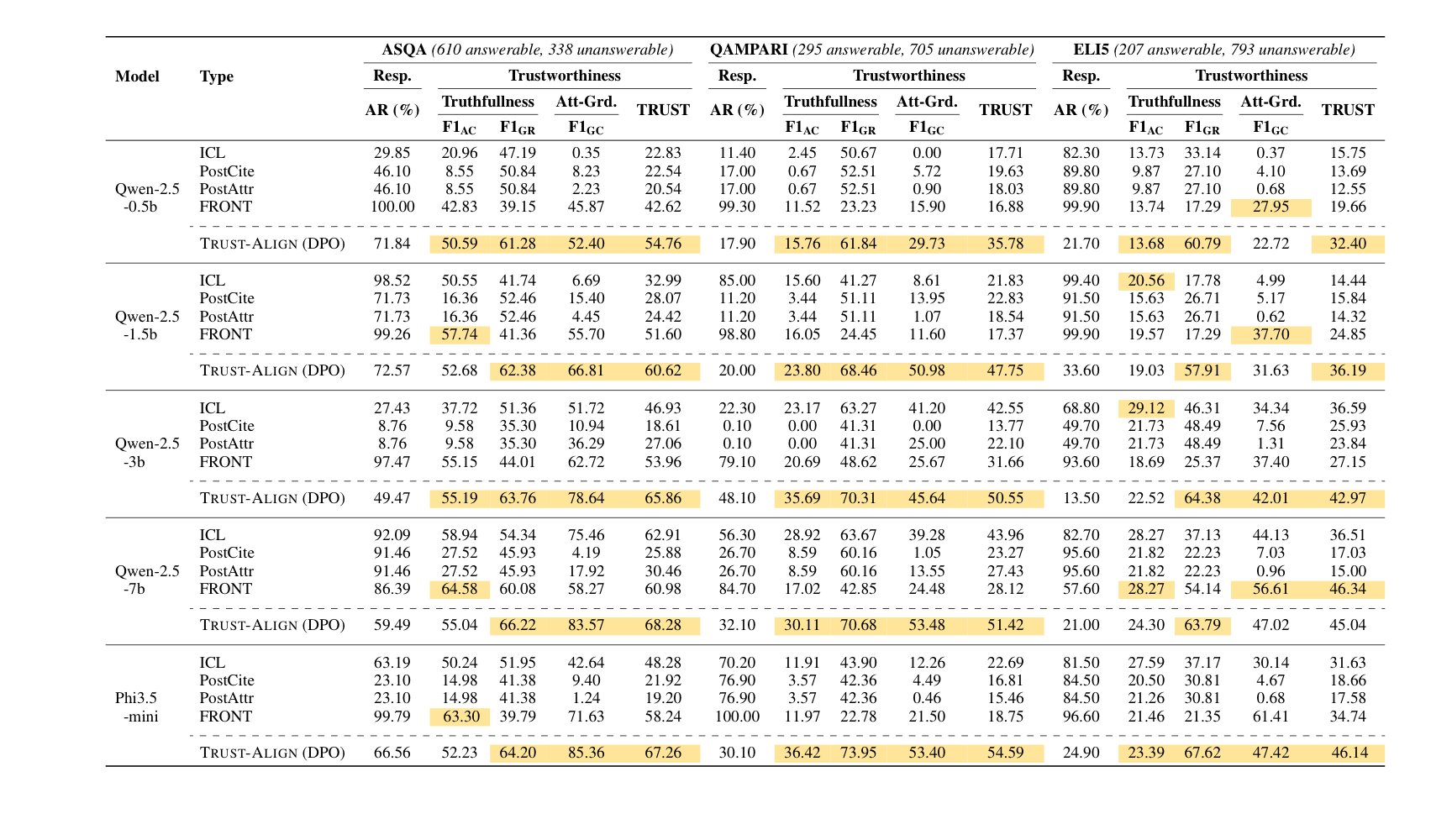
- Trust Score의 전반적인 증가 (26/27)
- 모든 27개 실험에 대해, grounded refusal (모르는 것을 모른다고 말하는 능력)이 크게 상승
- 27개 중 24개 실험에 대해서, 정확한 citation을 생성하는 능력이 개선
- 데이터셋에 따라, 정답 정확도는 개선되기도, 크게 개선되지 않기도 하였음.
- 정답 정확도를 개선하는 효과는 미미했다.
- 모델이나 모델의 파라미터 크기가 바뀌어도 공통적으로 성능 개선이 있었음.
- SFT보다 DPO로 훈련하는 것이 일반적으로 더 높은 성능 향상이 있었음.
<Expert QA에 대한 OOD 실험 결과>
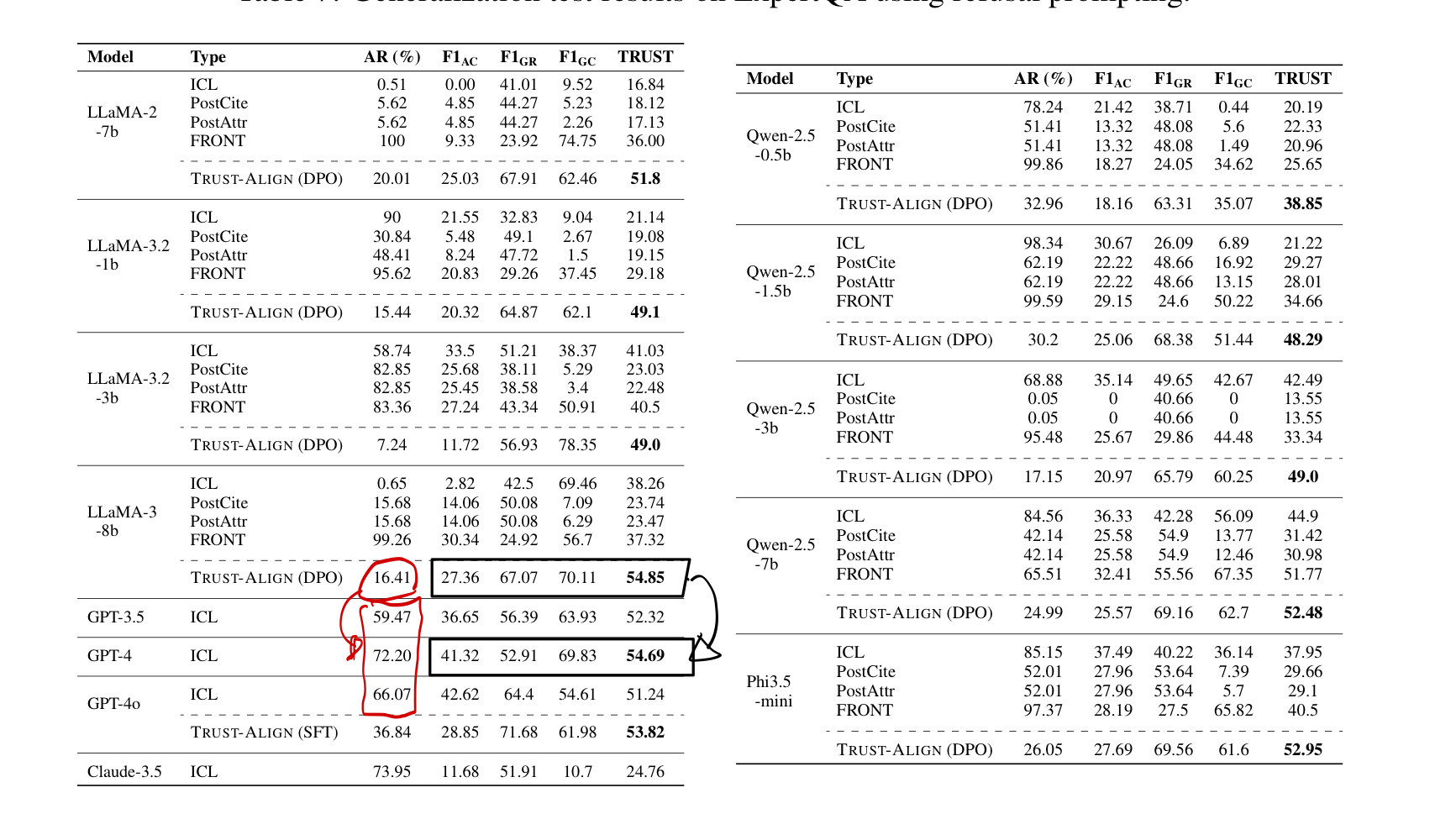
- Llama-3-8b가 gpt-4, gpt-4o보다 더 높은 trust score를 기록!
- Answer Correctness가 gpt-4, gpt-4o보다 떨어지나, refusal 및 citation 정확도가 상승
- 답변율을 볼 때, gpt-4 및 gpt-4o는 parametric knowledge를 이용하여 답변 정확도를 높이는 모습을 보임.
얻은 인사이트
- gpt-4와 같은 거대한 closed-source 모델이라도, RAG 태스크에 있어 최적화 되어 있지는 않다.
- 모르는 것을 모른다고 하는 능력, citation을 올바르게 생성하는 능력 등이 완벽하지 않다.
- 거대한 모델이 대답을 할 때에는 parametric knoweldge를 사용하는 경우가 많다.
- 모르는 것을 모른다고 하는 능력, citation을 올바르게 생성하는 능력은 DPO를 통해 크게 개선할 수 있다.
- RAG에서 그냥 비싼 LLM을 쓴다고 만사형통 해결되지 않는다.
- 작은 LLM도 고품질의 데이터셋으로 파인튜닝 된다면 RAG에 있어서 거대한 closed-source LLM의 성능에 비견될 수 있다.
- 결론적으로, RAG task에 꼭 알맞게 행동하기 위한 LLM의 파인튜닝은 매우 필요하다!